IntArray vs Array feat. 자바 바이트코드
코딩테스트를 풀다 보면 IntArray나 Array< Int >와 같이 반환값의 타입을 지정해주기도 합니다. 문제를 풀다보니 List가 되어버려 바로 반환하지 못 해 IntArray로 바꿨지만 오류가 났던 적 있으시다면 이 포스팅이 도움이 될 것입니다. 그 뿐만 아니라 코틀린의 타입을 자바의 관점에서 살펴보는 포스팅입니다.
코틀린과 Primitive 타입
primitive 타입을 지원하지 않는 코틀린
코틀린은 모든 타입을 클래스로 정의합니다. 자바에서 넘어온 사람이라면 의아할 내용입니다. 왜냐하면 자바는 Primitive 타입을 지원하기 때문입니다. 자바에서는 int, double과 같은 Primitive 타입을 기본적으로 지원하고, 이들을 감싸는 Integer, Double과 같은 Wrapper 클래스를 제공하여 Wrapper타입도 제공합니다. int와 같은 Primitive 자료형은 공간을 적게 차지하고 빠른 반면, Integer와 같은 참조형은 Collection의 원소로 사용할 수 있고, 다양한 편리한 기능을 제공합니다. 두 타입의 차이로 인해, 둘 모두 없으면 안 되는 중요한 녀석들입니다. 그렇다면 Primitive 타입을 지원하지 않는 코틀린은 공간/시간 복잡도를 포기한 것일까요? 그렇지 않습니다! 코틀린이 Primitive 타입을 지원하지 않는다는 말은 반만 맞는 말입니다. 이를 살펴보기 위해선 코틀린의 컴파일 과정에 대해서 살펴보아야 합니다.
코틀린의 컴파일 과정
컴파일은 일종의 번역입니다. 컴퓨터는 0과 1로 이루어진 기계어만을 이해할 수 있습니다. 컴퓨터에게 직접적으로 소통을 하기 위해서는, 컴퓨터가 이해할 수 있는 명령어를 떠올리고, 이 명령어와 대응되는 이진수를 입력해야 하는 것입니다. 이는 불편하고 비효율적입니다. Hello World를 출력하기 위해서 한 세월이 걸릴 것입니다. 이 문제를 해결하기 위해, 기계어로 번역이 될 수 있는 C와 자바, 코틀린과 같은 고급 언어가 등장하게 되었습니다. 이렇게 우리가 작성한 고급 언어를 컴퓨터가 이해할 수 있는 언어로 번역하는 과정을 컴파일이라고 합니다.
컴파일을 하면 기계어가 되는 것은 아닙니다. 각 언어마다 컴파일의 과정은 다르기 때문에, 여기서는 자바와 코틀린의 컴파일 과정에 초점을 맞춰 설명하도록 하겠습니다. 우선 자바는 JVM이라는 가상 머신을 사용합니다. 운영체제와 실행하려는 프로그램 사이에 가상 머신을 두어 OS에 종속적이지 않도록 합니다. 각기 다른 OS에 맞는 코드를 작성하는 대신, 가상 머신이 이해할 수 있는 소스 코드를 작성하게 됩니다(Write Once, Run Anywhere). 이 소스 코드는 가상 머신이 이해할 수 있는 바이트 코드로 컴파일됩니다. 이 바이트 코드를 가상 머신은 OS가 이해할 수 있는 기계어로 다시 컴파일합니다. 즉, 자바나 코틀린으로 작성된 코드는 1차적으로 자바 바이트 코드로 컴파일되어 JVM 위에 올라가게 됩니다. 이 바이트 코드를 각기 다른 OS가 이해할 수 있는 기계어로 컴파일 하는 것입니다.
코틀린은 자바의 단점을 보완하기 위해 만들어진 언어입니다. 자바는 JVM을 기반으로 승승장구하게 되었습니다. 성공을 이룬 만큼 다른 기술들을 받아들이는데 소극적이었습니다. (물론 이는 이전 버전들과의 호환성을 유지하는데 이점이 있습니다. ) 예를 들어, 파이썬은 2004년에, C#은 2007년에 받아들인 람다 표현식을 자바는 Java8( 2014년 ) 업그레이드에서야 지원하기 시작했습니다. 이외에도, 상대적으로 긴 코드 길이, NPE(Null Pointer Exception)과 같은 단점들을 가지고 있습니다. 이러한 문제들을 해결하고자 코틀린은 만들어졌습니다.
코틀린은 현명했습니다. 자바는 여러 단점들을 가지고 있었지만, 자바는 거의 20년 가까운 세월 동안 점유율에서 1위를 차지했고 그에 따라 축적된 데이터가 많습니다. 이를 기반으로 JVM은 안정적이라는 평가 받고 있습니다. 여기서 이 장점들을 가져오고자, 코틀린은 JVM을 선택함과 동시에 자바와 상호 운용이 가능하도록 설계했습니다. 여기에 덧붙여, 코루틴, 확장 함수, 널 안정성을 가져와 개발자가 효율적이고 안정적인 코드를 작성할 수 있도록 했습니다.
결론적으로 자바와 코틀린은 기계어로 컴파일 되기 전에, JVM이 이해할 수 있는 바이트 코드로 컴파일됩니다. JVM은 바이트 코드를 컴파일할 때, 그 코드가 어떤 언어로 작성된 클래스 파일인지 신경쓰지 않습니다. JVM 입장에서는 자바나 코틀린은 차이가 없습니다. 즉, 어떤 바이트 코드로 컴파일되는지 살펴본다면, Primitive 타입을 대하는 두 언어의 차이를 엿볼 수 있을 것입니다.
좀 더 복잡한 컴파일 과정(자바와 코틀린 코드가 함께 있는 프로젝트)에 대해서 알고 싶다면 다음에서 살펴볼 수 있습니다.
타입 확인 방법
1. 바이트 코드 까보기
IntelliJ를 기준으로 바이트 코드를 보는 법을 설명하도록 하겠습니다. 상단의 Tools > Kotlin > Show Kotlin Bytecode 를 선택하여 바이트 코드를 볼 수 있습니다. IntelliJ에서는 다양한 기능을 제공합니다. 코틀린 코드에 커서를 옮기면, 그 해당 코드가 어떻게 컴파일되었는지 알려줍니다. 또한 DECOMPILE 버튼을 누르면 해당 바이트코드에 해당하는 자바 코드를 보여줍니다. 우선 IntArray를 살펴보겠습니다. 왼쪽이 코틀린 코드, 오른쪽이 자바 바이트 코드입니다. 다음의 자바 바이트 코드는 다음과 같은 행동을 합니다.

1️⃣ L0
=> 레이블은 특정 코드 위치를 식별하는 이름이나 숫자입니다. 이를 점프 명령어와 함께 사용하여 실행 흐름을 제어합니다.
2️⃣ LineNumber 558 L0
=> L0 레이블과 558번 줄의 코드와 연관시킵니다.
3️⃣ ICONST_5
=> 스택의 상단에 5를 넣습니다. 이는 이후에 만들 IntArray의 크기로 전달됩니다.<br
4️⃣ NEWARRAY T_INT
=> 스택의 최상단에 있는 값을 가져와 Int형 배열을 생성합니다.
5️⃣ ASTORE 0
=> 새 배열을 로컬 변수 슬롯에 저장합니다.
DECOMPILE 버튼을 누르면 다음과 같이 자바 코드가 나옵니다. 다시 말해, 이렇게 컴파일하기 전에는 아래와 같은 자바 코드였다는 것입니다.
오 재미있습니다! 우리는 IntArray를 바이트 코드로 만들고, 이 바이트 코드를 다시 Decompile해서 자바 코드로 만들었습니다. 근데 우리가 알기로는 코틀린은 Wrapper 클래스만 다룹니다. 그렇기에 Integer와 같은 Wrapper 클래스를 예상하는 것이 타당해보입니다. 하지만 해당 바이트 코드는 Primitive 타입 배열을 자바 코드로 Decompile 되었습니다. 즉, 자바의 int[]와 코틀린의 IntArray가 같은 코드로 번역되어 JVM이 보기엔 차이가 없다는 것입니다. 좀 더 알아봅시다.
다음은 Array< Int >입니다. 이전에 살펴보지 않은 코드들을 위주로 살펴보겠습니다.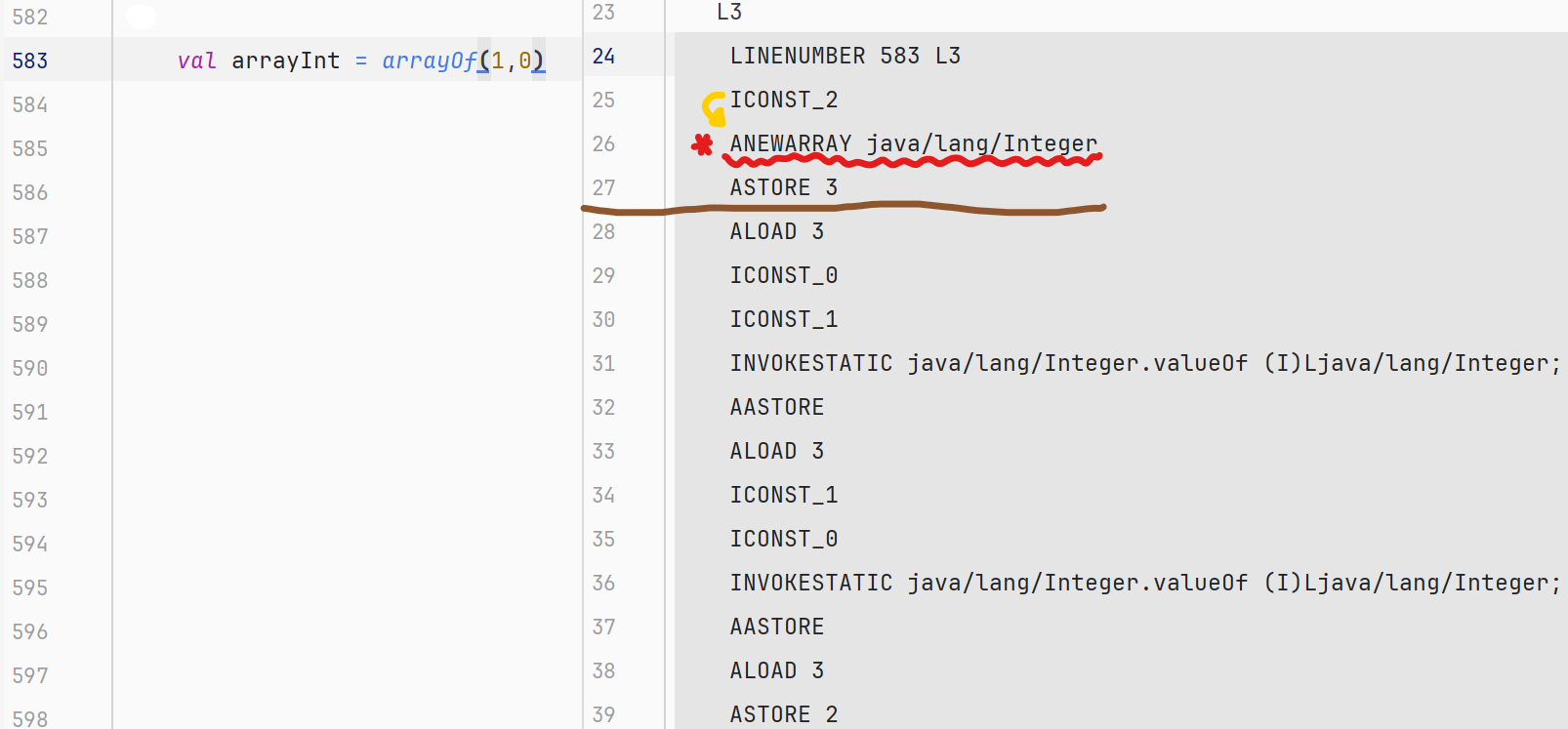
23번부터 27번째 줄까지는 밑줄 친 ANEWARRAY java/lang/Integer 제외하고는 완전히 같다는 것을 알 수 있습니다. 이후는 스택에 인덱스와 값들을 저장하고 이를 꺼내는 방법을 사용하여 Array의 값들을 초기화 하는 방법을 보여줍니다. IntArray와 달리, (31번, 36번 줄) Boxing을 위해 Integer.valueOf()를 호출하는 것을 알 수 있습니다. 이로 인해, 속도 차이가 발생합니다. 이 바이트 코드에 해당하는 자바 코드는 다음과 같습니다.
해당 바이트 코드는 자바의 Integer 배열로 변환되는 것을 알 수 있습니다. 아까와는 달리 이번엔 예상대로 코틀린의 Wrapper 타입이 자바의 Wrapper 타입의 코드와 같다는 것을 알 수 있습니다. 여기서 2가지를 유추할 수 있습니다. 하나는 NEWARRAY T_INT와 ANEWARRAY java/lang/Integer의 차이가 이러한 큰 차이를 만들어냈다는 것입니다. 이 말은 전자는 자바의 int 배열을, 후자는 Integer 배열을 해석한 자바 바이트 코드라는 것입니다. 그리고 코틀린의 IntArray는 자바의 int배열의 바이트 코드와 Array< Int >는 자바의 Integer배열과 같은 바이트 코드로 컴파일된다는 사실입니다. 즉, 컴파일러는 우리 몰래 IntArray와 Array< Int >를 구분하여 전자는 int[]와, 후자는 Integer[]와 같은 바이트 코드로 컴파일한다는 것입니다!!!
2. javaClass
javaClass 프로퍼티는 코틀린 표준 라이브러리에서 제공하는 확장 라이브러리입니다. 이를 통해, 클래스의 인스턴스가 속한 Java Class 객체를 알 수 있습니다. 즉, 어떤 코틀린 객체가 Java에선 어떤 클래스의 작품인지 알려줍니다. Java에서 getClass() 메서드를 사용하는 것과 유사합니다.

다음에서 볼 수 있듯이 이상한 형태로 출력되는 것을 알 수 있습니다. ‘[‘은 배열을 의미합니다. 여러 개 연속으로 나타나며 다차원 배열을 의미합니다. 그 뒤에 나오는 문자는 요소의 타입을 의미합니다. 즉, class [I는 int 배열을 의미하고 class[Ijava.lang.Integer;는 Integer 배열을 의미합니다. 이외의 내용은 다음의 getName 메서드의 설명에서 확인할 수 있습니다.
여기서도 자바 바이트 까보기와 같은 결과가 나왔다는 것을 알 수 있습니다. IntArray는 자바의 int[]와, Array< Int >는 JVM 관점에서는 같다는 것입니다.
번외) ctrl + shift + p
가끔, 우리가 작성한 코드가 무엇을 반환하는지 헷갈릴 때가 있습니다. map과 같은 타입을 써서 List<?> 반환되었거나, 초반부에 누가 만들었는지도 모르는 Map< ?, ? >을 만날 때가 있습니다. 이 때는 ctrl + shift + p 로 뭐하는 녀석인지 알 수 있습니다. ㅎ
Primitive type로 번역하는 코틀린
자바는 Primitive 타입과 Wrapper 타입을 명시적으로 구분합니다. 개발자는 필요에 따라 선택하여 사용해야 합니다.
코틀린은 이 구분을 가렸습니다. 대신 모든 타입을 클래스에 집어넣는 결정으로, Primitive가 아닌 Wrapper 타입만을 사용할 수 있도록 했습니다. 하지만 위의 바이트 코드에서 알 수 있듯이, IntArray는 int[]와 같은 바이트 코드로 컴파일되어 Primitive 타입을 사용하는 것 같은 효과를 냈습니다. 즉, 개발자는 이에 대한 구분을 할 필요를 없도록 했지만, 컴파일러가 그 고민을 대신하게 했다고 볼 수 있습니다.
컴파일러는 다음과 같이 판단합니다. IntArray로 만들어진 배열은 int[]와 같은 바이트 코드로 컴파일합니다. Array< Int >와 구분하면서 모든 타입을 클래스에 넣는 설계원칙과 속도 두 마리 토끼를 다 잡았다고 할 수 있을 것입니다.
코틀린은 이런 방식을 Int 클래스에도 적용했습니다. 컴파일러는 Int 타입의 Non-Null 값은 int와 같은 바이트 코드로 번역합니다. Int? 타입은 Integer와 같은 바이트 코드로 번역됩니다.

돌고돌아 여러가지를 말했지만, 결론적으로 똘똘한 컴파일러가 Integer[]와 int[]를 구분할 필요가 없도록 만들어주었습니다. 다만 속도가 중요하다면 Primitive 와 같은 바이트 코드로 사용되는 IntArray와 Int를 사용해야 합니다.
댓글남기기